计费与扣费说明
为了让大家更清晰地了解平台的扣费逻辑,本文将详细解释 Token 的概念、按次与按量计费的区别,以及缓存机制的运作方式。
一、先搞懂「Token」
1. 什么是 Token?
可以把 Token 当成 AI 模型聊天里的专属 “计价字数”。它和我们平时说的“字数”逻辑差不多,但更精准,是 AI 模型所有扣费的核心基础。
2. Token 换算规则
- 1个汉字 ≈ 2个 Token
- 1个标点符号(不管是逗号、句号、问号),都算 1个 Token
- 1个普通英文单词 ≈ 1个 Token。比如你发“hello”,就是 1个 Token;AI 回“thank you”,就是 2个 Token。
- 特别长的英文单词会被拆成多个 Token。比如“unhappiness”,会拆成“un”“happi”“ness”,就算 3个 Token。
注意:不管是你发的消息(输入),还是 AI 回复的消息(输出),每一个字符、每一个单词,都会被拆成 Token 进行统计。
3. 为什么按 Token 算钱?
AI 处理每一个 Token 都需要消耗算力,就像你用手机刷视频,视频越长越费电一样。你发的内容越长、AI 回复的内容越长,AI 消耗的算力就越多,扣费自然就围绕 Token 数量来计算。
二、按次计费 vs 按量计费
在模型广场中,不同的模型会有不同的计费标识,主要分为“按次计费”和“按量计费”。
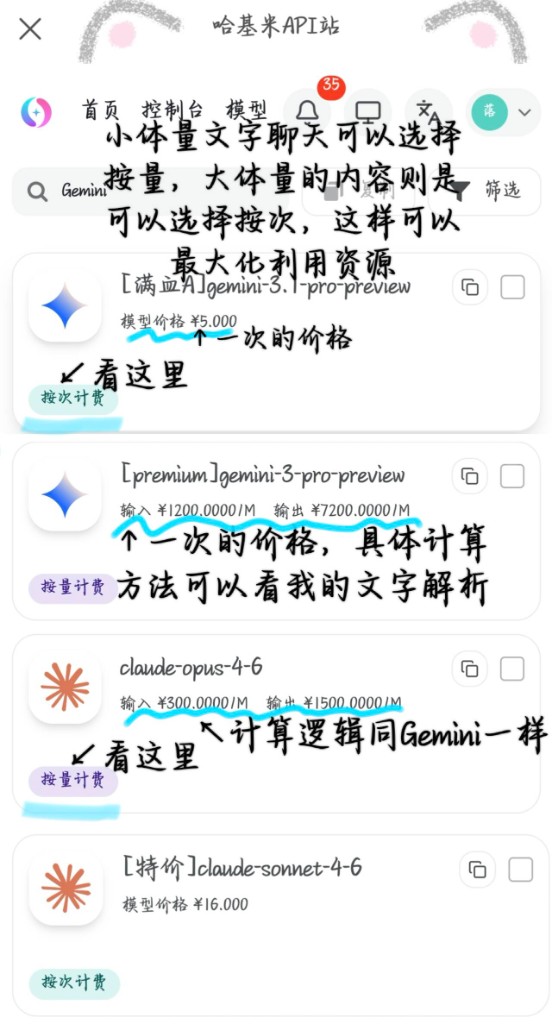
1. 按次计费(固定一口价)
一次对话只扣一笔固定费用,和你发了多少 Token、AI 回了多少 Token 完全没关系。说白了就是一次对话一口价。
示例:
[满血A]gemini-3.1-pro-preview模型,标注了【按次计费】,后面写的模型价格¥5.000,就是一次对话的固定价格。[特价]claude-sonnet-4-6模型,标注了【按次计费】,模型价格¥16.000,也是一次固定扣费。
怎么用最划算?
- 适合大体量内容:比如一次性让 AI 写一篇长文章、处理一个大文件、长篇对话。选按次,不管内容多长,只扣一次钱。
- 不适合简短聊天:哪怕只发 10 个 Token 问个小问题,也要付一次固定费用,性价比不高。
⚠️ 注意点:如果 AI 没正常输出内容(比如回空、报错了),也会扣除这次的固定费用。这是正常扣费,不是乱收费。
2. 按量计费(用多少算多少)
根据你发的 Token 数(输入)和 AI 回复的 Token 数(输出)分别计费。Token 越多,扣的钱越多,而且输入和输出的单价不一样(通常输出单价更高)。
示例:
[premium]gemini-3-pro-preview模型,标注【按量计费】,写了输入 ¥1200.0000/M,输出 ¥7200.0000/M(M 就是 100 万个 Token 的意思)。claude-opus-4-6模型,标注【按量计费】,写了输入 ¥300.0000/M,输出 ¥1500.0000/M。
计算公式:
一次对话总花费 = (输入 Token 数 × 输入单价) + (输出 Token 数 × 输出单价)具体计算案例(以
claude-opus-4-6为例):- 输入单价:每 100 万个 Token 收 300 块,算下来每个 Token
0.0003元。 - 输出单价:每 100 万个 Token 收 1500 块,算下来每个 Token
0.0015元。 - 假设你输入了 20 个 Token,AI 输出了 11 个 Token:
- 输入扣费:20 × 0.0003 = 0.006 元
- 输出扣费:11 × 0.0015 = 0.0165 元
- (再结合下文的缓存打折,最终可能只需要 0.0567 元左右)
- 输入单价:每 100 万个 Token 收 300 块,算下来每个 Token
三、缓存机制(省钱利器)
在同一个窗口和 AI 连续聊天时,系统会把之前聊过的内容存起来,这就是缓存。下次再发消息时,系统不用重新计算所有历史内容,直接读取缓存,费用就会大幅打折。
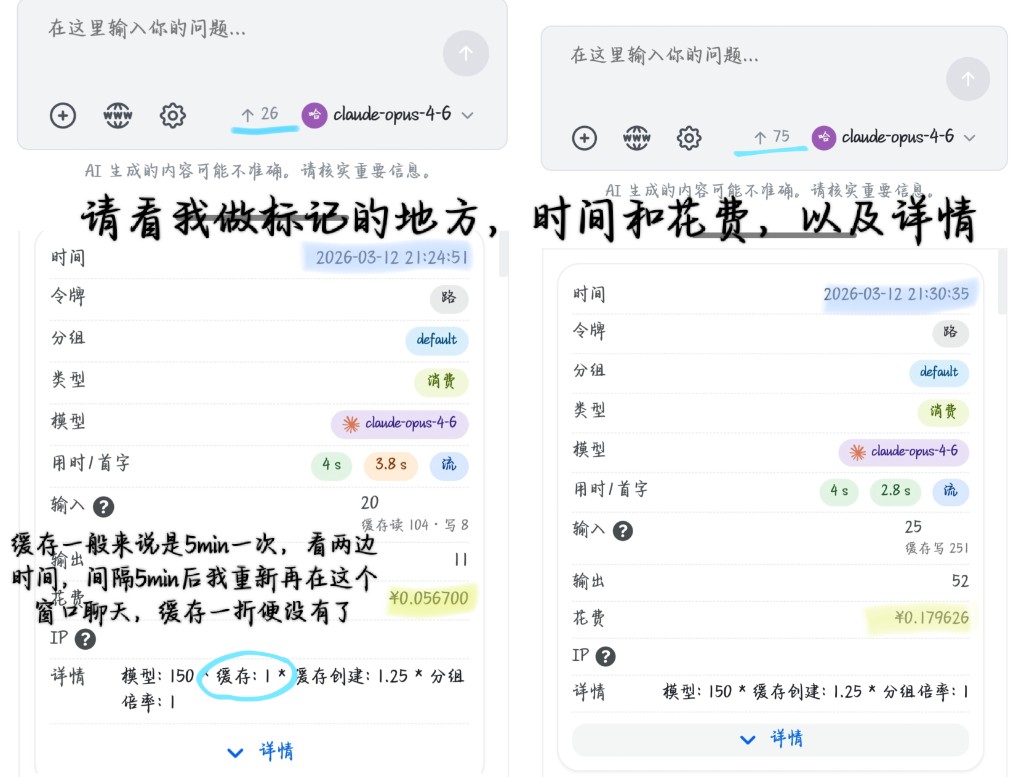
1. 缓存倍率状态解析
状态1:缓存命中(详情显示
缓存: 1)- 对应上方左图。详情里写着
缓存: 1,以及缓存读104·写8,意思是系统成功读取了旧缓存,历史内容按正常折扣收费。 - 结合规则,相当于历史内容只收 1 折的钱,能帮你省下 90% 的历史对话费用!
- 对应上方左图。详情里写着
状态2:缓存未命中(详情显示
缓存创建: 1.25)- 对应上方右图。详情里写着
缓存创建: 1.25,以及缓存写251,意思是系统没有读取到旧缓存,而是重新创建了新缓存,此时按全额计费。
- 对应上方右图。详情里写着
2. 为什么缓存会失效?
缓存本质是系统识别你“是不是接着聊”的标识,只要标识变了,缓存就会失效。常见原因有 4 个:
- 原因1:聊天间隔太久
- 缓存有效期一般是 5 分钟。超过 5 分钟不发消息,系统就会自动清除缓存,下次聊天只能全额计费。
- 解决:同一个窗口聊天,尽量在 3-5 分钟内连续发,别断太久。
- 原因2:隐性参数变化
- 比如后台自动切换了模型版本、加了验证标识,虽然你没手动改,但系统觉得是新对话,缓存就失效了。
- 解决:固定用一个模型,别频繁切换。
- 原因3:上下文结构变动
- 哪怕你没改设置,长篇聊天后,上下文结构发生变化,系统识别不到旧缓存,就会显示
缓存创建:1.25。 - 解决:长篇对话别一直挤在一个窗口,超过 10w Token 就新开窗口。
- 哪怕你没改设置,长篇聊天后,上下文结构发生变化,系统识别不到旧缓存,就会显示
- 原因4:手动改了设置/历史
- 中途改了角色卡、删了某条历史对话,缓存的“匹配标识”就变了,会导致失效。
- 解决:同一个窗口聊到底,不换模型、不改角色卡、不删历史。
四、省钱使用指南总结
- 选对计费方式
- 简短聊天、小体量 Token 需求:选按量计费。
- 大体量聊天、长篇内容、文件处理:选按次计费(固定扣费,不按 Token 叠加,更划算)。
- 选模型前先看模型广场的标注:标注“按次”就按次用,标注“按量”就按量用。
- 固定窗口
- 同一个窗口聊到底,不中途换模型、不改角色卡、不删历史,保持缓存持续生效,享受 1 折优惠。
- 长篇对话拆窗口
- 一次性单段对话超过 10w Token(约 5w-6w 字),就新开个窗口,避免 AI 处理不过来或缓存结构失效。
💡 一句话省流:
- Token:AI 的计价字数,1个汉字/标点/单词 ≈ 1个 Token。
- 按次计费:一次固定扣费,适合大体量内容。
- 按量计费:用多少算多少,适合简短聊天(拿4.6Claude举例:输入300/百万、输出1500/百万)。
- 缓存:5分钟内连续聊、不改设置,历史对话打 1 折。长篇记得拆窗口!