哈基米 API 站全模型分类及特点一览
为了方便大家在众多的模型列表中挑选最适合自己使用场景的模型,本文根据哈基米 API 站现有的主要模型矩阵进行了详细的分类与特点总结。
一、 Gemini 系列(谷歌旗下核心多模态模型)
Gemini 系列是本站的特色模型,具有强大的多模态(图像输入/解析)和角色扮演能力。根据不同的渠道资源,主要分为“满血系列”与“官逆系列”。
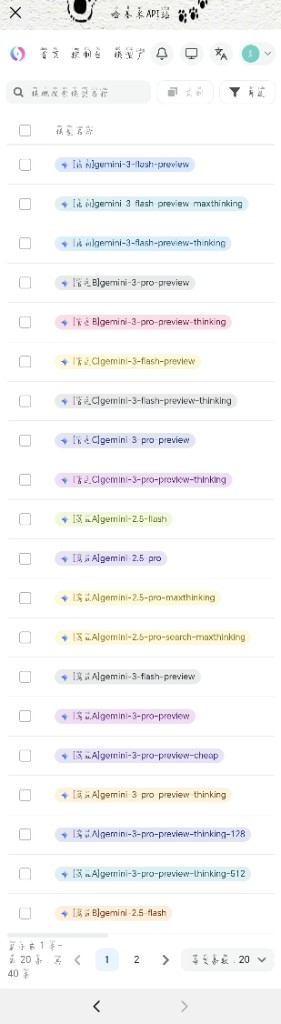
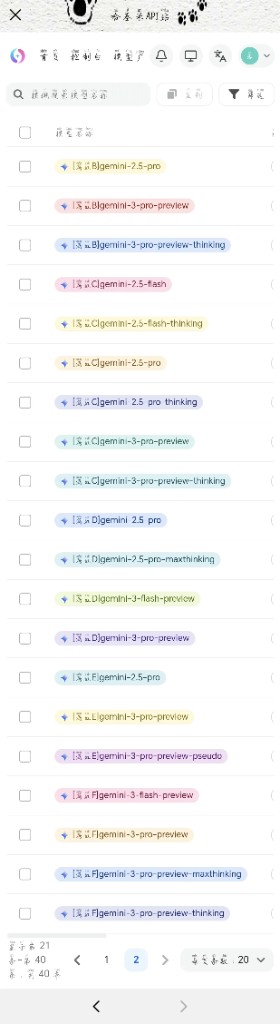
1. 核心系列前缀
- [满血] 系列: 资源拉满无配额限制。根据字母变体不同,性格和智商有所差异。
- [满血D]: 智商顶配且稳定,适合复杂推理。
- [满血A]: 性格温柔,极度适配角色扮演(RP)场景。
- [满血C]: 破甲难度最高,逻辑严谨,通常拒绝违规请求。
- [满血F]: 顺从性极强(好破甲),但相对容易出现截断或空回。
- [官逆] 系列: 逆向对接官方接口。性价比高且不易掉格式,非常适合手机端的角色扮演场景(性能略逊于满血)。
2. 常见版本后缀
- preview(预览版): 正式发布前的测试版本,可抢先体验新特性,但可能缺少文件上传等部分工具。
- -128 / -512: 代表支持 128k 或 512k 的超长上下文窗口。尤其是 512k 版本,非常适合长篇文档解析和极长设定的小说创作。
- thinking / maxthinking: 支持深度逻辑推导的“思考”版本。maxthinking 进一步强化了推理能力,适合数学题、代码调试等复杂逻辑任务。
二、 Claude 系列(Anthropic 旗下长文本专精模型)
Claude 系列以其极其优秀的文笔、细腻的情感刻画和出色的长文本逻辑著称,是角色扮演和内容创作的标杆。
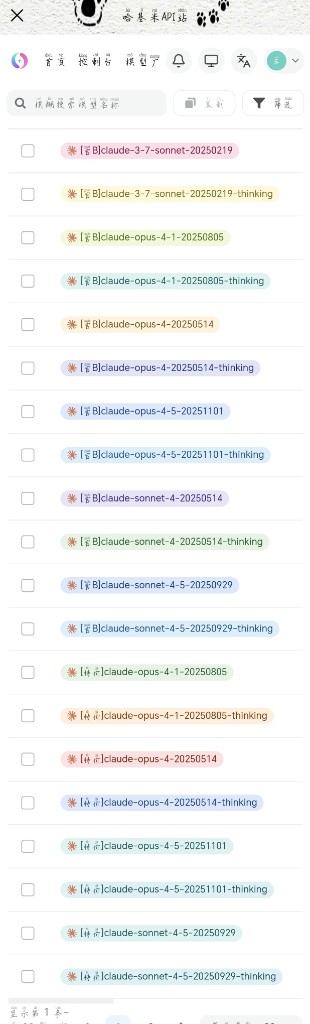
1. 核心变体
- Opus 系列: 旗舰顶配版本,推理能力强、输出质量极高,适合专业学术推导、大型文本和深度的剧情创作。 (注:部分带有
[特价]前缀的版本大幅降低了调用成本,性价比极高) - Sonnet 系列: 在性能与成本之间取得完美平衡,是大多数人日常使用和角色扮演的绝对主力版本。带有
[官B]前缀的版本为官方原生接口,稳定性有保障。 - Haiku 系列: 轻量提速版,响应速度最快、调用成本最低,适合简单的闲聊对话或短文本生成等轻量化场景。
2. 常见版本后缀
- 日期后缀(如 -20251101): 代表模型的具体迭代更新日期。越新的日期通常意味着修复了旧 Bug,并提升了整体的推理精度。
- thinking: 深度推理版本。启用了类似 O1 的多步骤推导逻辑(Chain of Thought),输出内容的逻辑性和完整性远超基础版,专为极度复杂的任务设计。
三、 Grok 系列(马斯克旗下 xAI 实时专精模型)
Grok 系列以反叛精神、幽默感以及强大的实时搜索能力为卖点,并且基本没有安全审查(极易破甲),可以放心使用于各类无限制场景。
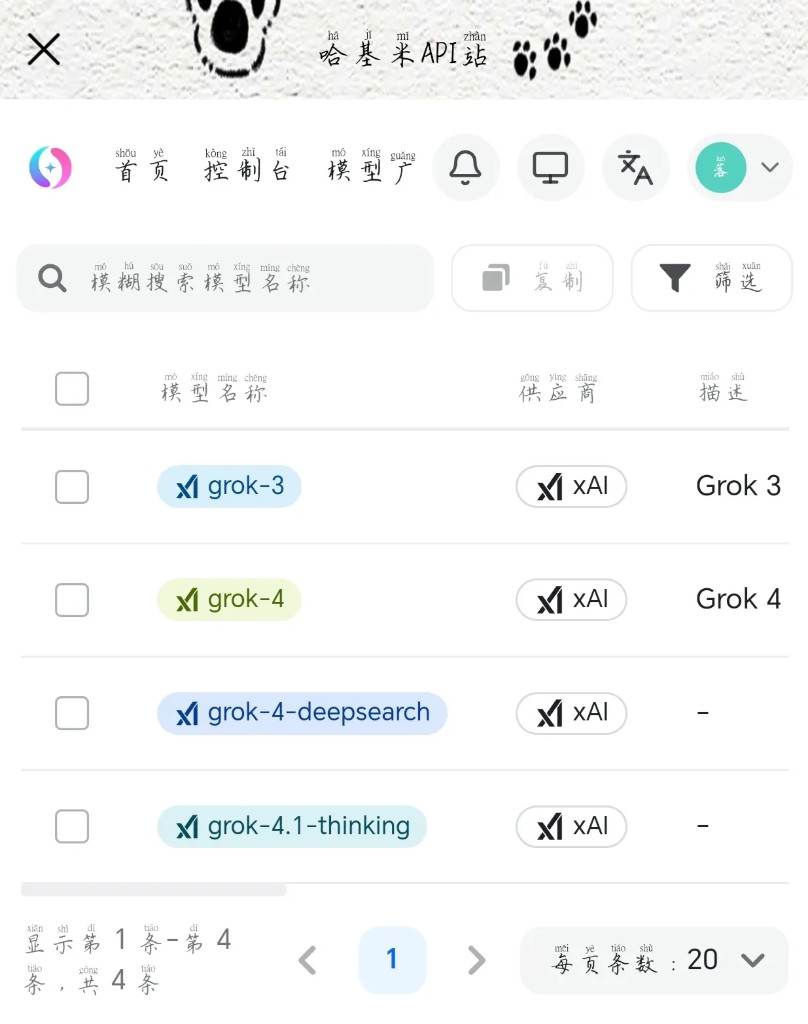
核心特点
- 基础版(grok-3 / grok-4): 简洁实用,无额外功能增强,保留官方原生核心能力。响应速度极快,适合日常咨询与无障碍的 RP 对话。
- Deepsearch(深度搜索版):
grok-4-deepsearch集成了深度的联网搜索功能,能获取最新的时事、新闻、股票等数据信息,适合事实性查询和热点分析场景。 - 流式体验优异: 部分版本支持“真·开流输出”,内容实时生成显示,互动体验极其流畅。
四、 DeepSeek 系列(国内极高性价比开源模型)
DeepSeek 被誉为“国产之光”,以极低的价格提供了逼近国际顶尖大厂模型的逻辑推理能力。
核心变体
- 主版本(v3.1-terminus / v3.2): 数字越大功能越新,通用能力强大。
- R1 满血推理版(如 r1-0528): 代表特定日期的迭代版(小鲸鱼)。大幅优化了响应速度和复杂的数理逻辑推理,在极度复杂的角色设定扮演中也有非常惊艳的表现。
- OCR 专项版(deepseek-ocr): 光学字符识别专项版。擅长图片中的文字提取、复杂排版的扫描件识别,解析精度显著高于普通的多模态大模型。
五、 Qwen 系列(通义千问专项优化模型)
Qwen 阿里系模型,这里的变体主要针对特定生产力场景进行了极致优化。
专项版本
- qwen3-coder-480b: 4800亿参数的代码专项版。精通多语言编程、大型项目开发、代码调试与重构,是程序员的绝佳编程助手。
- qwen3-embedding-8b: 专注文本向量化。输出的向量可直接用于语义检索、相似度计算、构建企业级知识库等底层基建。
- qwen3-reranker-8b: 重排序优化版。对检索出的结果进行深度的语义层面重新排序,大幅提升 RAG(检索增强生成)搜索或问答系统的结果精准度。
六、 其它特色小众模型
除了主流大厂模型,本站还提供了一些极具潜力的新兴模型供开发者和研究者使用。
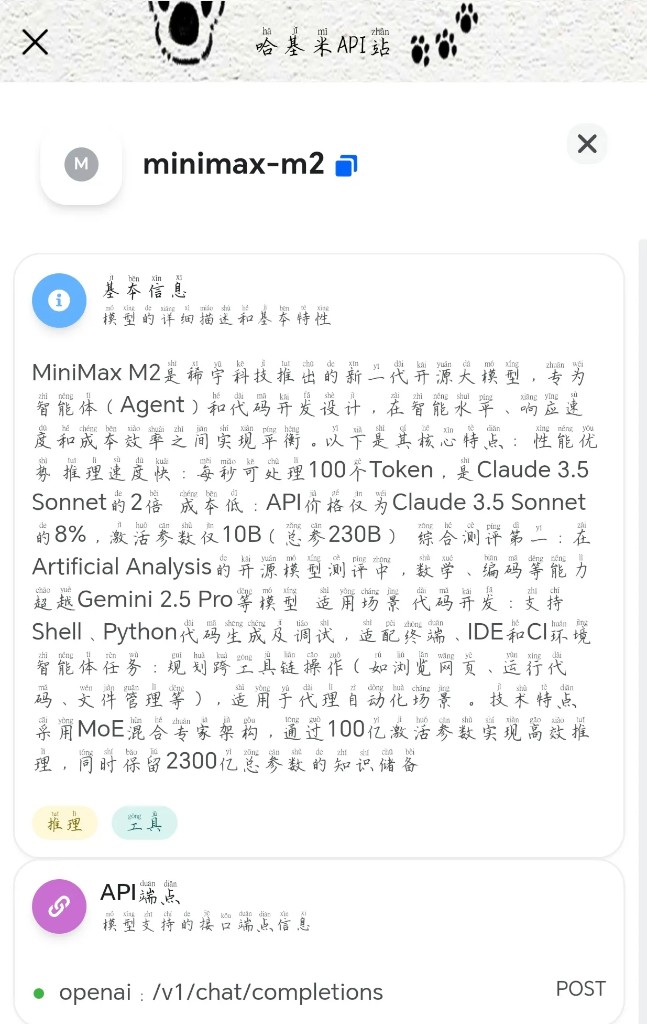
- MiniMax M2: 并非大家熟知的国产语音模型星野,而是稀宇科技推出的新一代开源大模型,专为智能体(Agent)和代码开发设计。它的核心优势是极快的推理速度(每秒 100 Tokens,是 Claude 3.5 Sonnet 的两倍),同时 API 成本仅为前者的 8%。它能够规划跨工具链的操作(如浏览网页、运行代码),非常适合轻量化自动化场景。
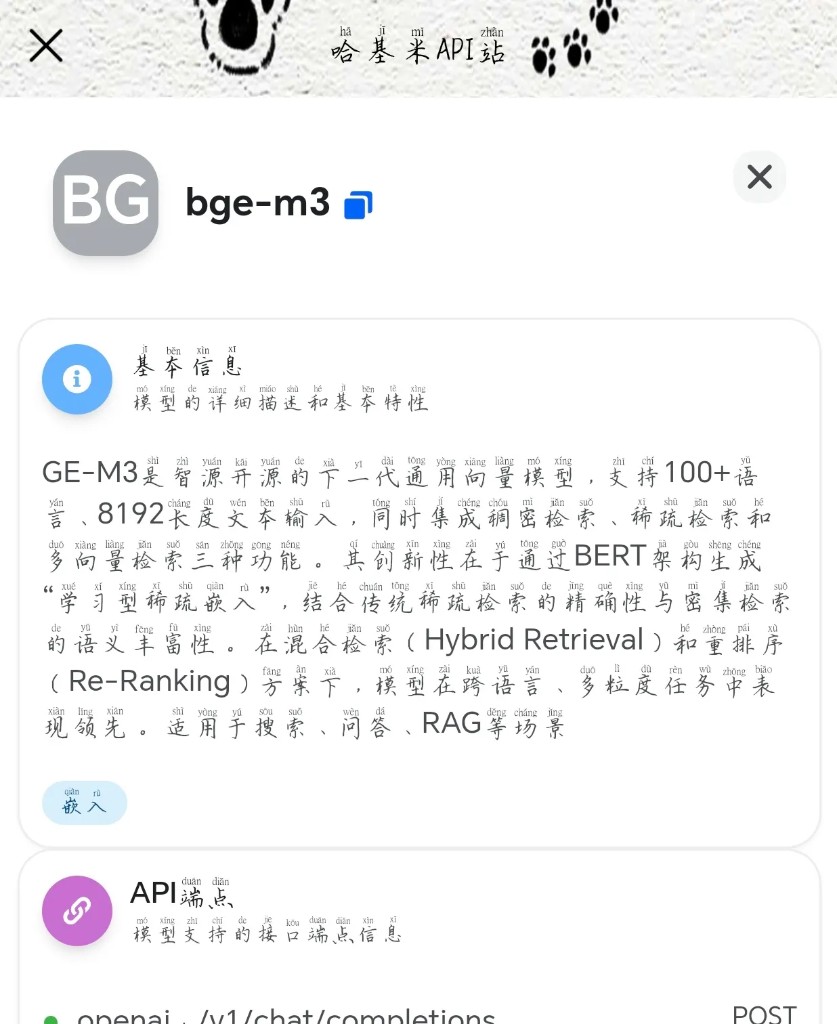
- BGE-M3: 智源开源的下一代通用向量模型。支持 100+ 语言和 8192 长度文本输入。它通过 BERT 架构生成“学习型稀疏嵌入”,集成了稠密检索、稀疏检索和多向量检索三种功能。如果你在做多语言问答或 RAG 知识库,这个模型是不二之选。
感谢所有用户对哈基米 API 站的支持,祝大家使用愉快! ⌯>𖥦<⌯ಣ