常见问题解答 (FAQ)
常见报错代码与排查
Q:报错提示 “正在加号请稍等” 是什么意思?
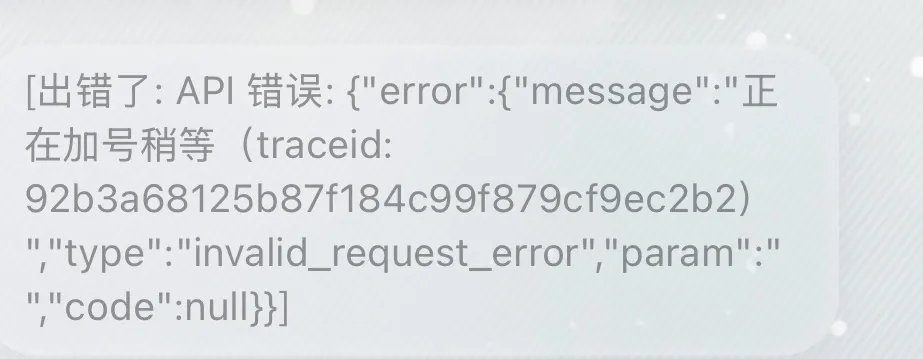
A: 出现这个报错,说明当前该模型所在的上游渠道账号库存/额度暂时耗尽,导致无法继续响应 API 调用。
解决方法:
- 方案一: 这属于上游渠道的问题,请耐心等待管理员在群内发布修复完毕的通知。
- 方案二: 如果急需使用,建议在此期间暂时切换到其他模型进行对话。
Q:为什么模型只回复了几个字就立刻停止了?或者干脆空白回复?

A: 这种情况在角色扮演(RP)中通常被称为 “截断” 或 “空回” 。主要由以下几种原因引起:
触发了安全审查(最常见) 模型在生成内容的过程中触发了官方的安全内容审查机制(Safety Filters),强制通过截断来阻止不当内容(如 NSFW)的继续生成。
- 解决方法: 检查自己的提示词(Prompt)/ 预设是否包含强力的破限指令。推荐使用专门针对该模型优化的破限预设(例如 kemini 和 lzumi 破限)。
上下文过长(Token超载) 当单次请求携带的上下文太长(例如超过 30k 或 50k tokens)时,会大幅增加触发截断的概率。
- 解决方法: 进行自检并精简上下文。建议使用自动隐藏或自动总结插件(如酒馆的 Amily 助手)来控制上下文长度。
并发调用与软件兼容性 如果你使用的是像“小手机”或“lovemo”之类的第三方客户端软件,它们在请求时往往会发起并发调用,这极易导致接口空回。此外,部分软件底层陈旧的实现逻辑也会增加截断与空回的几率。
服务器负载过高 模型上游服务器出现网络抖动、负载过高,或同一时间并发使用人数过多,这也是不可避免的客观因素之一。
Q:为什么我在 API 配置界面显示“无效的 API 密钥”?
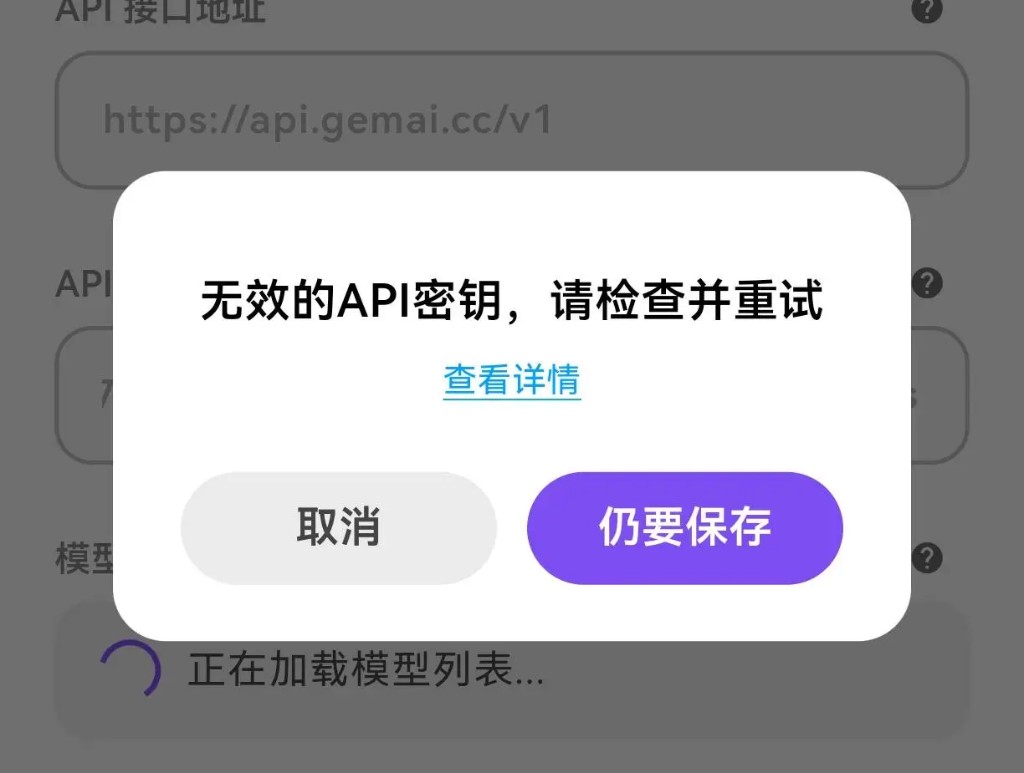
A: 出现这个提示,通常是因为填写的 API Key 格式不正确或权限受限。请按以下步骤排查:
检查复制是否完整 请仔细核对密钥是否复制完全。完整的密钥通常以
sk-开头。 特别注意:在覆盖旧密钥时,不要不小心把开头的sk-删掉了。检查限制设置 如果你确信密钥复制完整但仍报错,请回到控制台重新创建一个新的密钥。 在创建时,千万不要开启“IP 限制”和“模型限制”,保持默认的不限制状态。
重新复制并配置 创建新密钥后,再次点击复制按钮,确保内容完整无误地粘贴到软件的配置框中。
Q:为什么在使用时出现“分组下模型无可用渠道”的报错?

A: 出现这个报错说明**当前模型在上游渠道中暂时没号(额度耗尽或暂时下线)**了。
解决方法:
- 方案一: 耐心等待管理员补充账号或修复该渠道。
- 方案二: 暂时更换其他的模型进行调用。
Q:为什么客户端报错提示“插座断连(socket hang up)”?
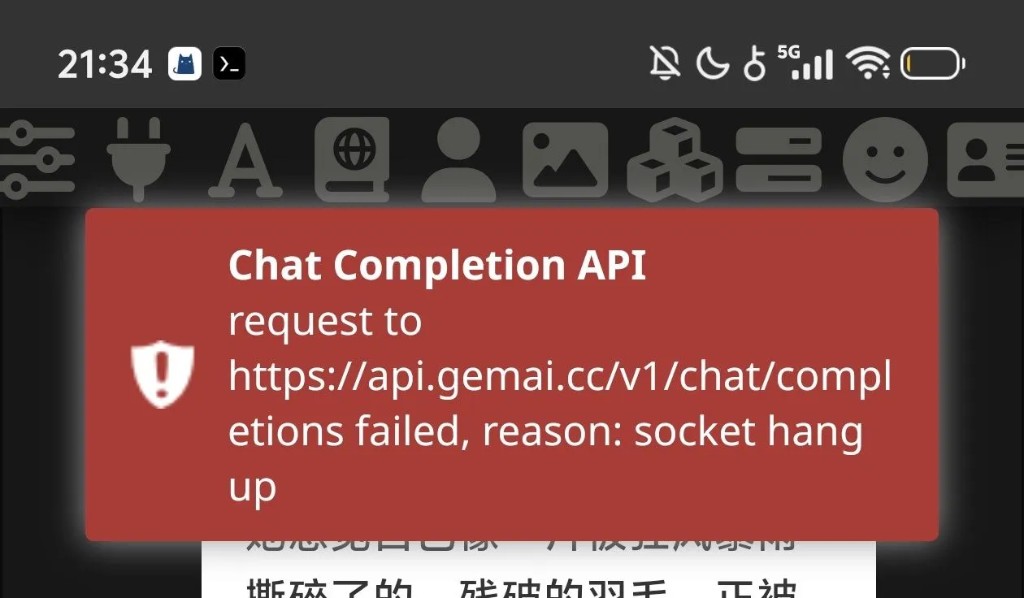
A: 出现 socket hang up 错误,通常代表你的本地客户端与服务器之间的网络连接被意外中断了。
排查建议:
- 检查网络环境:确认你当前连接的 Wi-Fi 或移动网络是否稳定。
- 关闭代理工具:绝大多数情况下,这是因为你在本地开启了代理工具(梯子/VPN)导致的请求被拦截或分流失败。请关闭梯子后,再次尝试发送请求。
Q:为什么模型在调用时显示“请求包含无效参数”?

A: 如果出现 Provider API error: Request contains an invalid argument 报错,通常有以下两种可能:
上游模型接口异常(最常见) 上游模型接口炸了或正在维护,导致无法正常解析请求。此时只能耐心等待恢复,或者先更换其他模型使用。 你可以尝试多重 roll(重试)几遍,如果偶尔能通说明是上游不稳定;如果一直不行,建议直接换模型。
客户端 API 配置问题 如果你使用的是 SillyTavern(酒馆)等前端客户端,也有极小概率是 API 配置参数填写有误,或者在安装酒馆时出了问题,导致发送了不兼容的请求。请检查 API 和模型名配置是否完全符合教程要求。
模型表现与回复质量
Q:为什么模型像发了疯一样,只发同一个字或者同一个符号?

A: 这种情况通常是因为你的**预设(Prompt)**出了问题。
主要原因在于你的预设里面没有防绝望和防情绪过激的指令,或者相关选项没有开启。尤其是官方默认的 Gemini 模型(哈基米)在防绝望和反过激方面表现较弱,如果不加以限制,很容易陷入死循环,疯狂重复同一个字或符号。
- 解决方法: 强烈推荐所有人在游玩角色扮演(RP)时,都配置并开启一个成熟的破限预设(例如包含反绝望/防死循环指令的预设),以免再次出现类似情况。
Q:为什么明明是同一个模型,感觉今天比昨天要傻?
A:“昨天温如玉今天脑如残?” 这其实是由模型无记忆的本质和前端客户端的缓存、隐藏策略造成的:
大语言模型的无记忆性(每次都是“新建对话”) 大模型本身是没有记忆和状态的。每一次你发送消息,客户端都会把整个对话的所有上下文从头到尾重新发送一遍。模型根据它这次读到的所有内容重新理解并继续创作。上下文中一点微小的变化都会导致回复内容和风格不一样。这并不是特定渠道的问题,即便是直接调用官网的 Claude(如小克等)也会有同样的现象。
前端软件的“自动隐藏”机制(如 Tavo 插件) 许多前端客户端(例如酒馆的 Tavo 插件)都自带“自动隐藏”功能以节省 tokens。你可以观察自己的调用记录:如果前一条调用消耗了 50,000 tokens,而后一条突然只剩 10,000 tokens 了,这就说明它在自动隐藏前文。 这就代表,如果有些关键的人设、设定或情感转折点没被读到,模型就会对当前的设定产生误解,从而出现“变傻”、“脑残”或者脱离人设的问题。
- 建议: 检查你的前端上下文设置,适当调整自动隐藏的阈值,确保角色的核心设定和关键剧情不被截断隐藏。
计费与 Tokens 统计
关于 Claude 模型的缓存 Tokens 统计说明
在控制台查看使用日志时,你可能会注意到输入部分的统计分为了非缓存和缓存两部分。这是因为我们严格遵循了 Anthropic 的协议规范。
INFO
根据 Anthropic 协定:/v1/messages 的输入 tokens 仅统计非缓存输入,不包含缓存读取与缓存写入的 tokens。
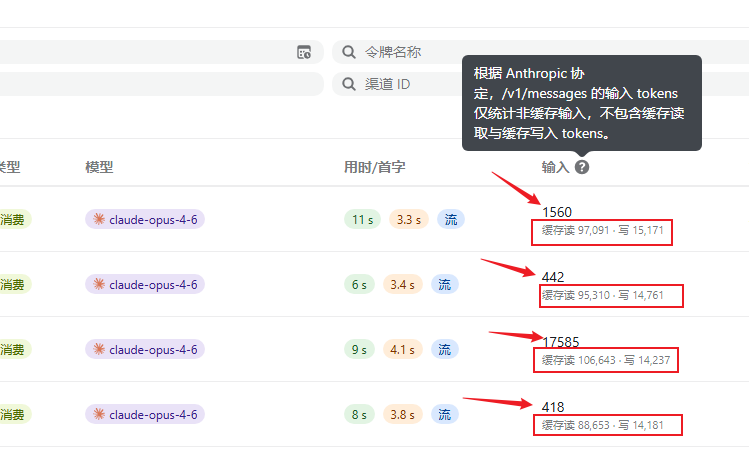
具体说明:
- 主输入数值(图中的大号数字): 这是你的非缓存输入 Tokens,即实际按照标准输入价格计费的 Tokens。
- 缓存读写数值(图中的小号字体): 这是被缓存系统命中的 Tokens。Anthropic 对于长上下文启用了 Prompt Caching 技术,命中缓存(缓存读)的 Tokens 价格会大大降低,而创建缓存(缓存写)会有特定的计费标准。为了清晰透明,我们在后台将它们拆分展示,但在主输入数据上,我们严格与官方对齐,仅统计非缓存部分。
SillyTavern 酒馆常见问题
Q:为什么我的聊天界面显示的是一大坨代码?
A: 因为你游玩的是一张包含前端渲染的卡片,既然有前端渲染的内容的话,那你就需要安装相对应的渲染工具或插件。
目前比较常见的工具有酒馆助手和小白X。 你可以参考这篇教程来安装并配置:关于酒馆助手 - 介绍与安装教程。
Q:为什么 AI 的回复里暴露了一大串思维链?怎么隐藏?

A: 回复里直接显示了思维链(如 <think>... 等标签及中间的过程),说明前端没有正确隐藏掉这部分内容。
排查与解决方法:
- 未安装/配置对应的正则:检查你的预设是否包含了配套的用于隐藏思维链的正则表达式。通常酒馆需要通过正则扩展来自动折叠或隐藏这些思考过程。
- 模型掉格式(未闭合标签):有时模型生成的标签没有包裹完全(例如有头无尾),会导致正则匹配失败,从而使思维链原样暴露出来。
- 建议: 在酒馆预设里面勾选**“防掉格式”**相关的选项,或者在对话框中发一条系统提示(如:“注意保持格式闭合”),重新生成一次通常就可以解决。